Vampires, Plots, and Interactivity - Oh My!
Brendan Mobley and Claire Arnold
INTRODUCTION
In 2005, we were introduced to a new saga that would change the lives of many. The Twilight Saga by Stephanie Meyer is a four part story full of love, blood, and heartbreak. For those who are unfamiliar, the story goes that highschooler Bella Swan moves to a small town in the Pacific Northwest and falls in love with brooding vampire Edward Cullen. The town is home to a whole clan of vampires and a feuding family of werewolves. The teenage angst of the early 2000s generation was fueled by these novels and the five-part movie rendition that hit theaters starting in 2008, and the series has overall has entered into the cultural consciousness.
In this project we decided to analyze the Twilight books and movies to see how the movie adaptations may have veered from the original works. We decided to answer these questions using text and sentiment analysis. There are a few things to be aware of before engaging with the rest of this post. The analysis and assumption we make are based entirely on text; that is book and movie scripts. With film, there is a LOT that goes into the production (lighting, set direction, the score, the mise en scene) that impacts the overall feeling. We understand, by embarking on this strange little project, that the conclusions we will be drawing are in many ways inherently flawed, simply because so much is lost from a film when you only look at the dialogue. We adjusted this a little bit by including sentiment analysis of the soundtracks to the movies. Regardless, we are using the basic skills we have and hope to make this enjoyable, and if you have ever been curious about the differences between the Twilight books and films, well, this is the post for you!
The other goal in this project was for us to learn for ourselves and show others how to engage with the R package Plotly. This package creates interactive, web-based graphs that are much more dynamic than anything that can be created with ggplot2. We’ll dive into more of the details about ggplot and plotly in a bit, right now we’re going to focus on our data and sentiment analysis!
First we need to read in all the data we are going to use to investigate the Twilight saga. Be warned: this section gets kinda technical. If this process does not interest you, and it likely does not, feel free to skip right to the “PLOTLY BASICS” section using the Table of Contents on the left.
READING IN DATA, TOKENIZING, ADDING SENTIMENTS
Here we find sources for the books, movies, and scripts, then make tokenized datasets for each of them. Tokenizing is the process of taking each string of words and breaking it down into a series of single words. This allows us to run our sentiment analysis on each individual word, and treat each one a single unit with a single sentiment. We’ll do this for each text we work with, as in books and scripts.
READING IN DATA
First we have to find our data sources. We are pretty sure that all the sites referenced are fully legal!
BOOKS
The full text of each book can be found at archive.org. The Twilight saga has its own page, and within it they have text files (.txt) for Twilight, New Moon, Eclipse, and Breaking Dawn.
The way these books are displayed on the website makes scraping them directly pretty easy. We do this with the rvest package, then we tokenize what we get into a dataframe we can use for sentiment analysis with tidytext functions. We display the process below, then repeat it for the rest of the books.
# saving the page url
twilight_url <- "https://archive.org/stream/Book3Eclipse/Book%201%20-%20Twilight_djvu.txt"
# scraping with rvest and selectors
twilight_text <- twilight_url %>%
read_html() %>%
html_node(css = "#maincontent > div > pre") %>%
html_text()
# making one big charater into actual dataframe
twilight_token <- tibble(text = twilight_text) %>%
# adding identifier
mutate(title = "Twilight") %>%
# tokenizing
unnest_tokens(input = text,
output = word,
token = "words")# new moon
newmoon_url <- "https://archive.org/stream/Book3Eclipse/Book%202%20-%20New%20Moon_djvu.txt"
newmoon_text <- newmoon_url %>%
read_html() %>%
html_node(css = "#maincontent > div > pre") %>%
html_text()
newmoon_token <- tibble(text = newmoon_text) %>%
mutate(title = "New Moon") %>%
unnest_tokens(input = text,
output = word,
token = "words")
# eclipse
eclipse_url <- "https://archive.org/stream/Book3Eclipse/Book%203%20-%20Eclipse_djvu.txt"
eclipse_text <- eclipse_url %>%
read_html() %>%
html_node(css = "#maincontent > div > pre") %>%
html_text()
eclipse_token <- tibble(text = eclipse_text) %>%
mutate(title = "Eclipse") %>%
unnest_tokens(input = text,
output = word,
token = "words")
# breaking dawn
breakingdawn_url <- "https://archive.org/stream/Book3Eclipse/Book%204%20-%20Breaking%20Dawn_djvu.txt"
breakingdawn_text <- breakingdawn_url %>%
read_html() %>%
html_node(css = "#maincontent > div > pre") %>%
html_text()
breakingdawn_token <- tibble(text = breakingdawn_text) %>%
mutate(title = "Breaking Dawn") %>%
unnest_tokens(input = text,
output = word,
token = "words")MOVIES
We found the script for Twilight, at scripts.com. The scripts itself was displayed in pages, which made scraping the script from the website directly rather difficult. Luckily they also had the script as a downloadable pdf, so we decided to use this format.
Reading in text off a pdf brings its own set of problems, but we have the pdftools package to help us out. Here we read in the data from the Twilight script pdf.
# reading in data from pdf
twilight_script_raw <- pdf_text("scripts/twilight_script.pdf") %>%
# making it legible
strsplit(split = "\n")Next we convert the script into a more useful format (list -> dataframe), then tokenize it as we did the books.
# converting to dataframe
twilight_script_token <- twilight_script_raw %>%
unlist() %>%
as.data.frame() %>%
# renaming the poorly named autogenerated variable
rename("text" = ".") %>%
# converting "text" from factor to character for tokenizing
mutate(text = as.character(text)) %>%
unnest_tokens(output = word,
input = text,
token = "words") %>%
# adding an identifying variable for use in larger dataset we are going to create
mutate(title = "Twilight")Unfortunately, scripts.com does not have the scripts for either New Moon or Eclipse, the next movies in the saga. We were able to find the script for New Moon at imsdb.com, this time in a format we could scrape right off the page using the rvest package.
# letsa go
newmoon_script_url <- html("https://www.imsdb.com/scripts/Twilight-New-Moon.html")
# scraping with rvest and selectors
# used selectorgadget chrome extention (http://selectorgadget.com/) to find path
newmoon_script_text <- newmoon_script_url %>%
html_nodes("pre") %>%
html_text()
# making one big charater into actual dataframe
newmoon_script_token <- tibble(text = newmoon_script_text) %>%
# adding identifier
mutate(title = "New Moon") %>%
# tokenizing
unnest_tokens(input = text,
output = word,
token = "words")Trying to find the script for the Eclipse movie brought about the same issue: it simply was not availible at imsdb.com. We were able to find it at transcripts.foreverdreaming.org, so this was the final Eclipse script that we used.
# this whole thing works
eclipse_script_url <- "https://transcripts.foreverdreaming.org/viewtopic.php?f=150&t=9147"
# scraping with rvest and selectors
eclipse_script_text <- eclipse_script_url %>%
read_html() %>%
html_node(css = "#p119175 > div > div.postbody") %>%
html_text()
# making one big charater into actual dataframe
eclipse_script_token <- tibble(text = eclipse_script_text) %>%
# adding identifier
mutate(title = "Eclipse") %>%
# tokenizing
unnest_tokens(input = text,
output = word,
token = "words")Breaking Dawn: Part 1 and Breaking Dawn: Part 2 were availible at our original source, scripts.com, in pdf format.
# first for part 1
# reading in data from pdf
breakingdawn1_script_raw <- pdf_text("scripts/breakingdawn1.pdf") %>%
# making it legible
strsplit(split = "\n")
# converting to dataframe
breakingdawn1_script_token <- breakingdawn1_script_raw %>%
unlist() %>%
as.data.frame() %>%
# renaming the poorly named autogenerated variable
rename("text" = ".") %>%
# converting "text" from factor to character for tokenizing
mutate(text = as.character(text)) %>%
unnest_tokens(output = word,
input = text,
token = "words") %>%
# adding an identifying variable for use in larger dataset we are going to create
mutate(title = "Breaking Dawn part 1")
# then for part 2
# reading in data from pdf
breakingdawn2_script_raw <- pdf_text("scripts/breakingdawn2.pdf") %>%
# making it legible
strsplit(split = "\n")
# converting to dataframe
breakingdawn2_script_token <- breakingdawn2_script_raw %>%
unlist() %>%
as.data.frame() %>%
# renaming the poorly named autogenerated variable
rename("text" = ".") %>%
# converting "text" from factor to character for tokenizing
mutate(text = as.character(text)) %>%
unnest_tokens(output = word,
input = text,
token = "words") %>%
# adding an identifying variable for use in larger dataset we are going to create
mutate(title = "Breaking Dawn part 2")SOUNDTRACKS
The soundtrack data was all taken from Genius, which has their own package that allows us to load in soundtracks as dataframes that are ready to be tokenized and cleaned up for analysis.
# making dataset of all the albums
soundtrack_names <- data.frame(artist = c("Various Artists",
"Various Artists",
"Chop Shop Records",
"Various Artists",
"Various Artists"),
album = c("Twilight (Original Motion Picture Soundtrack)",
"The Twilight Saga: New Moon (Original Motion Picture Soundtrack)",
"The Twilight Saga: Eclipse (Original Motion Picture Soundtrack)",
"The Twilight Saga: Breaking Dawn, Pt. 1 (Original Motion Picture Soundtrack)",
"The Twilight Saga: Breaking Dawn – Part 2 (Original Motion Picture Soundtrack)"))
# reading in albums from genius, so cache = TRUE
soundtracks <- soundtrack_names %>%
add_genius(artist, album) %>%
mutate(album = factor(album),
album = fct_inorder(album))
# tokenizing for sentiment analysis
soundtracks_token <- soundtracks %>%
unnest_tokens(output = word,
input = lyric,
token = "words")ADDING SENTIMENTS
Now that we have datasets for each title in each medium, we are ready to add sentiments! We do this with sentiment lexicons.
WHAT IS A LEXICON?
In text analysis, a lexicon is a big list of words that each have a sentiment attached to them. To tackle the questions of how the sentiments in the Twilight books and movies compare, we used two different sentiment lexicons. The first we use is the Bing lexicon, which gives a binary view of sentiments by word, giving us two categories of “positive” and “negative.” This is great for getting just a broad overview, but the important thing to remember is context matters, and this lexicon does not necessarily account for the context of each word. For more in depth sentiment analysis, we use the NRC lexicon, which gives “positive” and “negative”, as well as a whole slew of other sentiments that we can use to really grasp the feeling of the books and movies. Both of these lexicons live inside the tidytext package.
BING
The basic process of adding a lexicon to a dataset is rather simple, and is demonstrated below. The final dataset only contains words that were both in the intial dataset and in the lexicon, so adding a lexicon also removes any tokens in the dataset that are not words useful for sentiment analysis. These include names, objects, and more.
# reading in bing lexicon
bing <- get_sentiments("bing")
# making the dataset with sentiments
twilight_bing <- twilight_token %>%
inner_join(bing, by = "word")We repeat this process for the other mediums (datasets) so we have sentiments for all of them.
# rest of the books
# making all the individual senitimented datasests
# starting with New Moon because already did twilight
newmoon_bing <- newmoon_token %>%
# adding bing sentiment
inner_join(bing, by = "word") %>%
# summarizing to just ratio, keeping title
group_by(title) %>%
count(sentiment) %>%
mutate(prop = n/sum(n))
# repeating for rest of books
eclipse_bing <- eclipse_token %>%
inner_join(bing, by = "word") %>%
group_by(title) %>%
count(sentiment) %>%
mutate(prop = n/sum(n))
breakingdawn_bing <- breakingdawn_token %>%
inner_join(bing, by = "word") %>%
group_by(title) %>%
count(sentiment) %>%
mutate(prop = n/sum(n))
# making saga dataset for bing lexicon
saga_bing <- bind_rows(twilight_bing,
newmoon_bing,
eclipse_bing,
breakingdawn_bing)
# SOUNDTRACKS
soundtracks_bing <- soundtracks_token %>%
inner_join(bing, by = "word")Since we are much more interested in the sentiments of the NRC lexicon, we will not spend time creating a Bing dataset for the movies.
NRC
Adding sentiments from the NRC lexicon is very similar to adding from Bing, as shown below. We’ll repeat the process for every book, movie, and soundtrack since this lexicon will give us much more detailed information for in depth sentiment analysis. Since the most interesting analysis is done through comparing sentiments across titles, we will also make combined datasets which have sentiment information for all the titles in each medium (i.e. all four books, all five movies, all five soundtracks).
# BOOKS
# reading in lexicon
nrc <- get_sentiments("nrc")
# making the dataset with new sentiments
twilight_nrc <- twilight_token %>%
inner_join(nrc, by = "word") %>%
# then wrangle into format useful for graphing
group_by(title) %>%
count(sentiment) %>%
mutate(prop = n/sum(n))
# repeat for remaining books
# new moon
newmoon_nrc <- newmoon_token %>%
inner_join(nrc, by = "word") %>%
group_by(title) %>%
count(sentiment) %>%
mutate(prop = n/sum(n))
# eclipse
eclipse_nrc <- eclipse_token %>%
inner_join(nrc, by = "word") %>%
group_by(title) %>%
count(sentiment) %>%
mutate(prop = n/sum(n))
# breaking dawn
breakingdawn_nrc <- breakingdawn_token %>%
inner_join(nrc, by = "word") %>%
group_by(title) %>%
count(sentiment) %>%
mutate(prop = n/sum(n))
# putting all the books togther
saga_nrc <- bind_rows(twilight_nrc,
newmoon_nrc,
eclipse_nrc,
breakingdawn_nrc) %>%
# removing n because we never use it
select(-n)
# MOVIES
# twilight
twilight_script_nrc <- twilight_script_token %>%
inner_join(nrc, by = "word") %>%
group_by(title) %>%
count(sentiment) %>%
mutate(prop = n/sum(n))
# new moon
newmoon_script_nrc <- newmoon_script_token %>%
inner_join(nrc, by = "word") %>%
group_by(title) %>%
count(sentiment) %>%
mutate(prop = n/sum(n))
# eclipse
eclipse_script_nrc <- eclipse_script_token %>%
inner_join(nrc, by = "word") %>%
group_by(title) %>%
count(sentiment) %>%
mutate(prop = n/sum(n))
# breaking dawn part 1
breakingdawn1_script_nrc <- breakingdawn1_script_token %>%
inner_join(nrc, by = "word") %>%
group_by(title) %>%
count(sentiment) %>%
mutate(prop = n/sum(n))
# breaking dawn part 2
breakingdawn2_script_nrc <- breakingdawn2_script_token %>%
inner_join(nrc, by = "word") %>%
group_by(title) %>%
count(sentiment) %>%
mutate(prop = n/sum(n))
# putting all the movies togther
films_nrc <- bind_rows(twilight_script_nrc,
newmoon_script_nrc,
eclipse_script_nrc,
breakingdawn1_script_nrc,
breakingdawn2_script_nrc) %>%
select(-n)
# SOUNDTRACKS
soundtracks_nrc <- soundtracks_token %>%
# adding sentiment
inner_join(nrc, by = "word") %>%
# reducing to proportions for graphing
group_by(album) %>%
count(sentiment) %>%
mutate(prop = n/sum(n)) %>%
ungroup() %>%
select(-n) %>%
# standardizing names
mutate(album = case_when(
album == 'Twilight (Original Motion Picture Soundtrack)' ~ "Twilight",
album == 'The Twilight Saga: New Moon (Original Motion Picture Soundtrack)' ~ "New Moon",
album == 'The Twilight Saga: Eclipse (Original Motion Picture Soundtrack)' ~ "Eclipse",
album == 'The Twilight Saga: Breaking Dawn, Pt. 1 (Original Motion Picture Soundtrack)' ~ "Breaking Dawn part 1",
album == 'The Twilight Saga: Breaking Dawn – Part 2 (Original Motion Picture Soundtrack)' ~ "Breaking Dawn part 2"
)) %>%
rename(title = album)AGRESSIVE WRANGLING
We will also want to compare sentiments across mediums, i.e. between books and movies, etc. To do this we have to put together the datasets that we already have. Our only problem is with Breaking Dawn, which has two movies and two soundtracks (Breaking Dawn part 1 and Breaking Dawn part 2) but only one book. Using our extensive knowlege of the Twilight books and movies, we will manually split the book into sections that map to the content of the movie. This will be done by using stringr functions on the scraped text, then replacing the single Breaking Dawn book with our split versions.
# splitting book:
# parts 1+2 -> movie 1
# part 3 -> movie 2
# splitting the big character (whole book) into the two parts
breakingdawn_split <- str_split(breakingdawn_text, "BOOK THREE", 2)
# making into more useful dataframe
breakingdawn_split <- breakingdawn_split[[1]]
# splitting into parts one and two
breakingdawn1_book <- breakingdawn_split[1]
breakingdawn2_book <- breakingdawn_split[2]
# tokenizing them separately
breakingdawn1_token <- tibble(text = breakingdawn1_book) %>%
mutate(title = "Breaking Dawn part 1") %>%
unnest_tokens(input = text,
output = word,
token = "words")
breakingdawn2_token <- tibble(text = breakingdawn2_book) %>%
mutate(title = "Breaking Dawn part 2") %>%
unnest_tokens(input = text,
output = word,
token = "words")
# adding sentiments
breakingdawn1_nrc <- breakingdawn1_token %>%
inner_join(nrc, by = "word") %>%
group_by(title) %>%
count(sentiment) %>%
mutate(prop = n/sum(n))
breakingdawn2_nrc <- breakingdawn2_token %>%
inner_join(nrc, by = "word") %>%
group_by(title) %>%
count(sentiment) %>%
mutate(prop = n/sum(n))
# replacing single breaking dawn with breaking dawn 1 and 2
saga_nrc <- saga_nrc %>%
filter(title != "Breaking Dawn") %>%
bind_rows(breakingdawn1_nrc,
breakingdawn2_nrc) %>%
select(-n)After splitting the Breaking Dawn book into equivalent parts we can add the movie and soundtrack sentiments to the dataset. This gives us a dataset which can be used to make comparisons across mediums.
# renaming to book proportion to keep track of which prop is which
big_nrc <- saga_nrc %>%
rename(book = prop) %>%
# adding movie script proportion
left_join(films_nrc, by = c("title", "sentiment")) %>%
rename(movie = prop) %>%
# adding soundtrack proportion
left_join(soundtracks_nrc, by = c("title", "sentiment")) %>%
rename(soundtrack = prop) %>%
# giving an order to the titles
ungroup() %>%
mutate(title = fct_inorder(title))This dataset is not in the tidy format. Most plotly graphs will require a tidy dataset, so we will reformat using the tidyr package.
big_nrc_tidy <- big_nrc %>%
pivot_longer(cols = c(book, movie, soundtrack),
names_to = "prop_type",
values_to = "prop")It’s important to note that the only way this data joining process worked is because we used summarized versions of our datasets. Trying to join this many datasets is pretty hard on the computer if the datasets are really big, so trying to combine the tokenized verisons of all the movies, books, and soundtracks would probably not be a great idea.
PLOTLY BASICS
One of our goals with this project was the explore the R package Plotly. As mentioned earier, Plotly is a package that creates interactive plots. These graphs only work when the output is an html document, as you can’t add interactive graphs to a pdf and the graphs themselves work using JavaScript. The great features of plotly graphs include popups, as well as options to zoom, pan, and toggle between variables using the legend in the graph output.
There are a few ways to create a plotly graph, one is by making the graph directly using plot_ly() and other related functions, and another is by converting a ggplot2 graph directly into a plotly graph using ggplotly(). We heavily focus on the former option in this post.
FIRST EXAMPLE
An example of simple graph we can make with the bing dataset is the ratio of positive to negative words in twilight. This is how it might be done with ggplot2:
# how many of each sentiment
twilight_bing <- twilight_bing %>%
group_by(title) %>%
count(sentiment) %>%
# finding proportion
mutate(prop = n/sum(n))
# graphing
ggplot(twilight_bing,
mapping = aes(x = sentiment,
y = prop)) +
geom_col(width = 0.7,
color = "black",
fill = c("#B6BE9C", "#5E747F")) +
theme_bw() +
# coord_polar("y", start = 0) +
scale_y_continuous(limits = c(0, 0.65),
breaks = seq(0, 0.65, .05)) +
theme(
plot.title = element_text(size = 17,
color = "black",
hjust = 0.5),
plot.subtitle = element_text(size = 12,
hjust = 0.5,
lineheight = 0.5)) +
labs(title = "Ratio of Positive to Negative Sentiments",
subtitle = "Twilight",
x = "Sentiment",
y = "Proportion of the Book")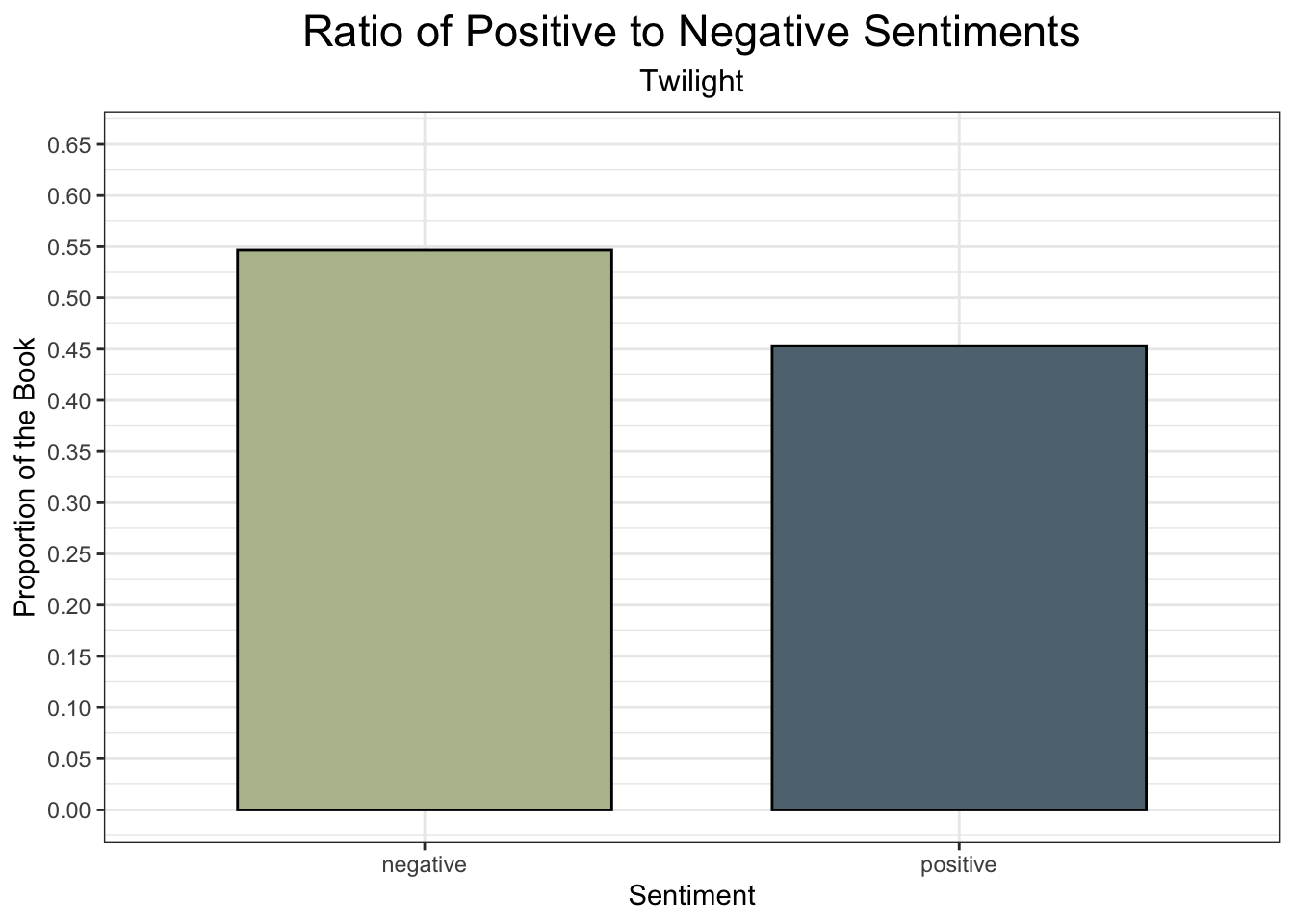
We can also graph this with plotly. If we are just interested in making a generic plot, we can just specify the x and y variables and plotly will use the geom that it thinks is best. These variables must be specified within the plot_ly() function, but no other information is needed besides the dataset.
# graphing
twilight_bing %>%
plot_ly(x = ~sentiment,
y = ~prop)Note the ~ before each variable (x = ~sentiment, y = ~prop). This needs to happen before variables in all aspects of plotly.
Plotly chose to use a bar plot to display the data that we gave it. This means that the biggest difference between the plotly plot and ggplot plot is the interactivity mentioned earlier, i.e. popups and viewing control. Note that these options were added automatically without any need for additonal code.
HOW DOES PLOTLY WORK
Plotly does a lot of work in JavaScript behind the scenes to create the interactive graphs in our output. That said, you dont need to know much of anything about JavaScript to use plotly. If you want to know more about how plotly makes graphs, check out the Interactive web-based data visualization with R, plotly, and shiny! This is a fantastic comprehensive resource that has a lot of great material on shiny. You could consider starting with section 2.2 - Intro to plotly.js, then moving on to other relevent sections.
PLAYING WITH PLOTLY
If we so desire, we can change the way plotly displays the content of the graph (geom) by specifying the geom that we want and adhering to its imput requirements. For example, with a pie chart, we cannot specify x or y variables, but instead just use values. We specify the geom for the graph with type = .
We can also remove the popup if it will not tell us anyting interesting, as well as modify other aspects of the graph with the layout() function.
We will demonstrate this with the Bing sentiments from the Twilight movie soundtrack! First we have to wrangle our big soundtrack dataset into shape then we can get right into graphing!
# making dataset of only words with sentiments from the twilight soundtrack only
soundtracks_bing_twilight <- soundtracks_bing %>%
# subsetting the dataset to just twilight
filter(
album == "Twilight (Original Motion Picture Soundtrack)"
) %>%
# getting proportion of positive to negative
count(sentiment) %>%
mutate(prop = n/sum(n)) # graphing with plotly
plot_ly(data = soundtracks_bing_twilight,
# not x or y
values = ~prop,
labels = ~sentiment,
type = "pie")It is worth noting that graphs can generally be made in a few ways with plotly(). The first is using a type = in a plot_ly() function as done above with type = “pie”. Another is using add_() in a new line, as done below with add_pie(). We use both ways of creating graphs in this post. The following code would produce the exact same graph as the chunk above.
plot_ly(data = soundtracks_bing_twilight) %>%
add_pie(values = ~prop, labels = ~sentiment)This is a perfectly acceptable pie chart, but its not perfect. In this case the content of the interactive popup would be better to just statically show inside the graph itself, as well as the content of the legend. We can do both of these things pretty easily - the content of the popup can be moved onto the graph itself with textposition = “inside”. The popup can then be removed with hoverinfo = “none”, and the legend removed with showlegend = FALSE. We also do not need the option to zoom on such a simple plot, so we will remove the option with the config() function. We can also add a title with the layout() function.
plot_ly(data = soundtracks_bing_twilight,
values = ~prop,
labels = ~sentiment,
type = "pie",
# moving text inside the pie
textposition = "inside",
textinfo = "label+percent",
# removing popup
hoverinfo = "none",
# removing legend
showlegend = FALSE) %>%
# adding title
layout(title = "positive/negative ratio in the twilight movie soundtrack") %>%
# removing options to zoom
config(modeBarButtonsToRemove = c("zoomIn2d", "zoomOut2d"))GGPLOTLY
This is the second way to create a plot in plotly - making a graph with ggplot2, then simply converting it into a plotly graph with code>ggplotly() of the Tidyverse. This is a super easy way to add interactivity to a plot. The compatability of plotly with the ubiquitous ggplot2 makes it much more accessable, as you effectively just need to know ggplot2 to be able to use the basic features of a plotly graph.
For example, we can make and store a graph of the NRC sentiments from the Twilight book with ggplot2:
# graphing, storing the graph as a variable to use in ggplotly()
twilight_nrc_graph <- ggplot(data = twilight_nrc,
mapping = aes(x = sentiment,
y = prop,
fill = sentiment)) +
geom_col(width = 0.7,
color = "black") +
coord_flip() +
theme_bw() +
theme(
plot.title = element_text(size = 17,
color = "black",
hjust = 0.5),
plot.subtitle = element_text(size = 12,
hjust = 0.5,
lineheight = 0.5),
legend.position = "none") +
labs(title = "NRC Sentiments in Twilight",
x = "Sentiment",
y = "Proportion of the Book")
twilight_nrc_graph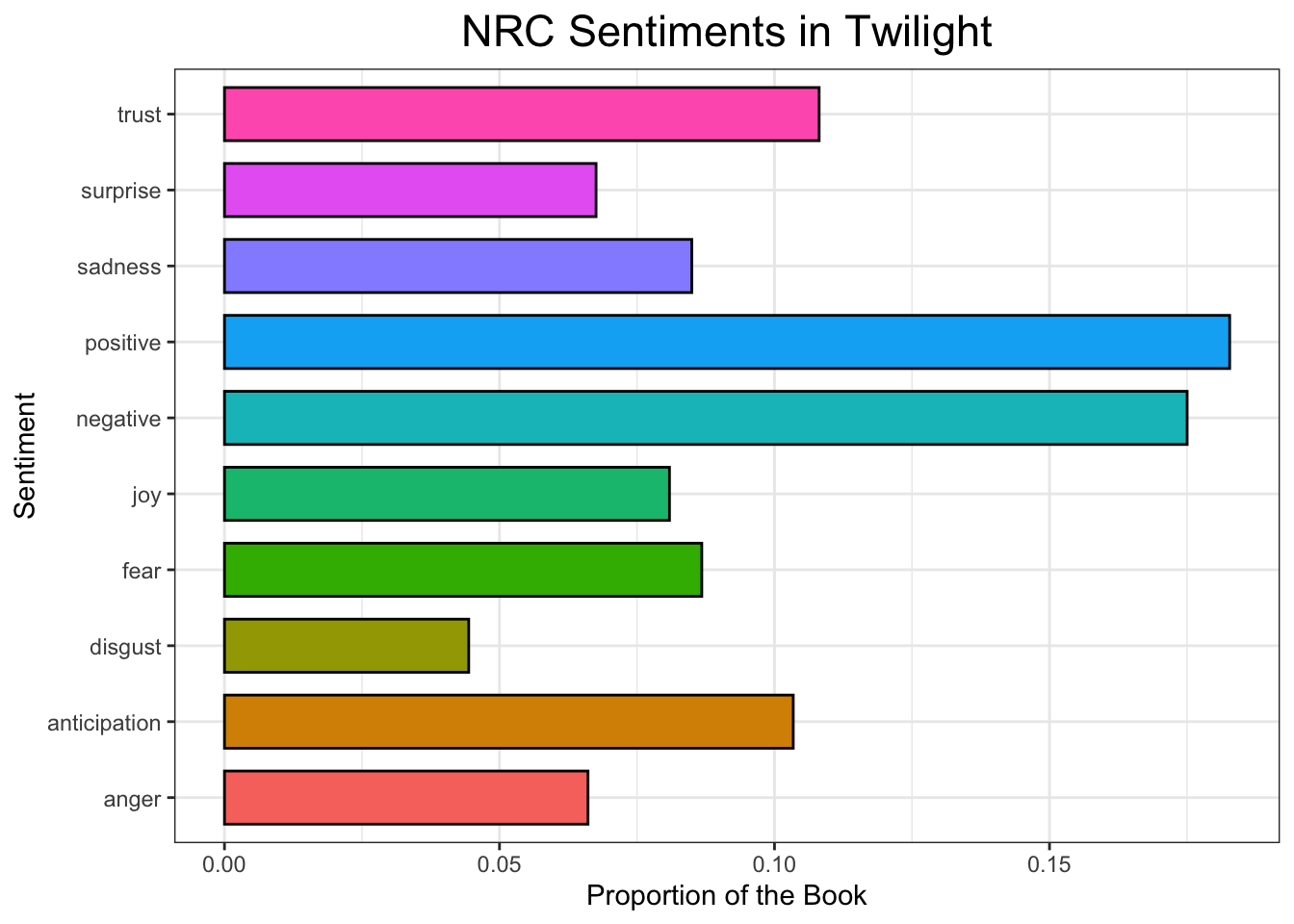
Then just specify the stored ggplot object (graph) in ggplotly() and the graph will be made into a plotly graph.
By default, the automatically generated pop-up shows all the information used to create the graphical representation that is shown on the graph. In this example, those would be sentiment and proportion, because those were our x and y variables. We can also specify the information contained in the popup as we did below.
# this is the graph we just made
twilight_nrc_graph %>%
# adding interactivity with ggplotly()
ggplotly(tooltip = "prop")
# note modified tooltipAs you can see we added a popup showing the exact proportion of the book made up by each sentiment, which keeps our axis looking clean while still providing precise information.
TOOLTIPS AND LEGENDS
Almost everything about a plotly plot can be modified in one way or another. One of the most important aspects to have control over is the pop-ups/tooltips. These can be changed either with the simple hoverinfo = , as done with the pie chart earier, or with more complicated and more customizable hovertemplate = . We use the second option below to reformat what is displayed in the popup of the graph.
The layout() function that we used earier can be used to change the appearence of the graph. Note that many of the inputs of the layout() function must be in list format, such as xaxis = , yaxis = , and legend = shown below. We changed the appearence of the legend rather easily by making a list of the wanted attributes, then imputting it within the layout() function.
We wil show these features with a simple line graph that would be much too complicated to be useful in ggplot2, but is parsed much more easily using the interactive elements of plotly. That said, Plotly has its limits as well, so we will graph just a few sentiments rather than all of them, because too many lines is too many lines.
# making list with legend styling contents
legend_style <- list(
font = list(
family = "sans-serif",
size = 12,
color = "#000"),
bgcolor = "#E2E2E2",
bordercolor = "#FFFFFF",
borderwidth = 2)
# initial wrangling
big_nrc_tidy %>%
filter(
sentiment == "joy" |
sentiment == "positive" |
sentiment == "trust"
) %>%
# graphing wrangled dataset
plot_ly(x = ~title,
y = ~prop,
color = ~sentiment) %>%
# adding lines
add_lines(linetype = ~prop_type,
# changing popup content - type and value only
# making variable mapped to linetype something we can put in popup
text = ~prop_type,
# more customizable way to do popups than hoverinfo
hovertemplate = paste('<b>Title:</b> %{x}',
'<br><b>Medium:</b> %{text}',
'<br><b>Proportion:</b> %{y}',
# getting rid of secondary textbox
'<extra></extra>')) %>%
# adding titles
layout(title = "Sentiments across titles, shown by medium",
xaxis = list(title = "Title"),
yaxis = list(title = "Proportion"),
# styling legend
legend = legend_style)SIDE BY SIDE PLOTS
Plotly has an easy way to show multiple plots side by side with the subplot() function. Plots displayed side by side in this manner retain their interactivity and share a single legend, effectively becoming one graph.
To use subplot(), simply make two separate plotly graphs, store them as variables, then plug them into the function like so:
# making graph 1
graph_1 <- big_nrc_tidy %>%
# choosing sentiments
filter(
sentiment == "negative" |
sentiment == "positive" |
sentiment == "joy" |
sentiment == "fear"
) %>%
# just books
filter(
prop_type == "book") %>%
# making the graph
plot_ly(x = ~title,
y = ~prop,
color = ~sentiment,
type = "scatter",
mode = "lines")
# making graph 2
graph_2 <- big_nrc_tidy %>%
# choosing sentiments
filter(
sentiment == "negative" |
sentiment == "positive" |
sentiment == "joy" |
sentiment == "fear"
) %>%
# just books
filter(
prop_type == "movie") %>%
# making the graph
plot_ly(x = ~title,
y = ~prop,
color = ~sentiment,
type = "scatter",
mode = "lines",
# hiding duplicate legend
showlegend = FALSE)# making the subplot
subplot(graph_1,
graph_2,
# standardizing the y axis
shareY = TRUE)This line graph uses the NRC sentiments lexicon to show the progression of proportion of words with joy, trust, and positive sentiment associations throughout the movies, starting with Twilight and ending with Breaking Dawn: Part 2. Each line represents a different medium; book, movie, or soundtrack. From this graph, the clearest trend we can see is that of positive sentiments across all mediums, where each medium tracks very closely. The proportion of positive words dips during Twilight: New Moon, which if you’re familiar with the plot does make sense, as Bella is thrown into a deep depression after Edward and his family flee town. However, the trend goes upwards for the remainder of the series. The progression for joyful words is interesting, as there is a fair amount of variation between each medium. The book and movie remain fairly low as far a joy goes, but the soundtrack has a much higher proportion of joyful sentiments than the other two mediums.
DEMOS
The interactive and web-based nature of plotly gives the user lots of ways to customize things about the graphs that they make. This means that while simple graphs are pretty easy (as shown in previous sections) things can get pretty complcated pretty fast. The following sections are primarily demonstrations of things that can be done with plotly, but the code is usually annotated so the reader can follow along more easily.
There are many many many types of interactive graphs that can be made with plotly. we will show a few of them, as well as offer our insights into the conclusions that can be drawn about the Twilight saga.
One example is the dumbbell plot, which shows changes between two conditions. We will graph the sentiments of the Breaking Dawn part 1 and part 2 movies to see how their sentiment’s differ.
# some initial wrangling
films_nrc %>%
filter(
title == "Breaking Dawn part 1" |
title == "Breaking Dawn part 2") %>%
# making dataset untidy to work with graph
pivot_wider(names_from = title,
values_from = prop) %>%
# making ordered for easier interperetation
mutate(sentiment = factor(sentiment,
levels = sentiment[order(`Breaking Dawn part 1`)])) %>%
# starting graphing
plot_ly(color = I("gray80")) %>%
# adding lines that will connect points
add_segments(x = ~`Breaking Dawn part 1`,
xend = ~`Breaking Dawn part 2`,
y = ~sentiment,
yend = ~sentiment,
showlegend = FALSE) %>%
# adding breaking dawn 1 point
add_markers(x = ~`Breaking Dawn part 1`,
y = ~sentiment,
name = "Breaking Dawn part 1",
color = I("pink")) %>%
# adding breaking dawn 2 point
add_markers(x = ~`Breaking Dawn part 2`,
y = ~sentiment,
name = "Breaking Dawn part 2",
color = I("blue")) %>%
# adding titles
layout(title = "Breaking Dawn Movies",
xaxis = list(title = "Proportion"))This plotly dumbbell plot shows net changes in proportions across each part of Breaking Dawn, the final installment of the series, for several sentiments. The film was broken into two parts because so much happens in the book (also capitalism). The biggest observable change is in anticipation between the Part 1 and Part 2, which matches with the plot, where a large battle scene takes place at the end of the second film. There’s not much particularly interesting in this plot, but it’s a really useful geom to use for tracking changes between two points of comparison.
Another type of graph we can make is the sunburst chart! this type of graph is not especially well suited to our datasets, so we will make one that sticks on the subject matter instead.
First we have to make the dataset, which, given the lack of specifically applicable data sources, is best done with extensive copying and pasting and editing by hand. For the record, this took as long as it looks like it did.
# gonna make graph with three parent sections (vampire, werewolf, human) and child sections for charaters that fall in these areas
# making the dataset
sunburst <- data.frame(
labels = c(
# innermost layer
"Humans",
"Werewolves<br>(shapeshifters)",
"Vampires",
# second layer - humans
"Charlie Swan",
"Renée Dwyer",
"Harry Clearwater",
"Billy Black",
"Tyler Crowley",
"Lauren Mallory",
"Mike Newton",
"Jessica Stanley",
"Angela Weber",
"Eric Yorkie",
"Emily Young",
"Sue Clearwater",
"Quil Ateara III",
"Rachel and Rebecca Black",
"J. Jenks",
# second layer - werewolf tribe
"Quileute tribe",
# second layer - vampires
"The Cullens",
"The Volturi",
"James' coven",
"Newborn army",
"Mexican coven",
"Amazonian coven",
"American nomads",
"Denali coven",
"Egyptian coven",
"European nomads",
"Irish coven",
"Romanian coven",
"Nahuel",
"Huilen",
# third layer - members of the werewolf pack
"Jakob Black",
"Sam Uley",
"Quil Ateara V",
"Embry Call",
"Paul Lahote",
"Jared Cameron",
"Leah Clearwater",
"Seth Clearwater",
"Collin Littlesea and Brady Fuller",
"Others<br>(never specified)",
"Ephraim Black",
# third layer - members of the covens
# the cullens
"Bella Swan",
"Edward Cullen",
"Carlisle Cullen",
"Esme Cullen",
"Alice Cullen",
"Emmett Cullen",
"Rosalie Hale",
"Jasper Hale",
"Renesmee Cullen",
# The Volturi,
"Alec",
"Marcus",
"Aro",
"Caius",
"Jane",
"Many Others<br>(never specified)",
# "James' coven"
"James",
'Victoria',
"Laurent",
# Newborn army
"Riley Biers",
"Bree Tanner",
# Mexican coven
"Maria",
"Lucy",
"Nettie",
# Amazonian coven
"Zafrina",
"Senna",
"Kachiri",
# American nomads
"Peter",
"Charlotte",
"Mary",
"Randall",
# Denali coven
"Eleazar",
"Carmen",
"Tanya",
"Kate",
"Garrett",
# Egyptian coven
"Tia",
"Amun",
"Benjamin",
"Kebi",
# European nomads
"Alistair",
"Charles",
"Makenna",
# Irish coven
"Siobhan",
"Liam",
"Maggie",
# Romanian coven
"Vladimir",
"Stefan"
),
parents = c(
# innermost layer: no parents
"",
"",
"",
# second layer - humans
rep("Humans", 15),
# second layer - werewolf tribe
"Werewolves<br>(shapeshifters)",
# second layer - vampires
rep("Vampires", 14),
# third layer - members of the werewolf pack
rep("Quileute tribe", 11),
# third layer - members of the covens
# the cullens
rep("The Cullens", 9),
# The Volturi,
rep("The Volturi", 6),
# "James' coven"
rep("James' coven", 3),
# Newborn army
rep("Newborn army", 2),
# Mexican coven
rep("Mexican coven", 3),
# Amazonian coven
rep("Amazonian coven", 3),
# American nomads
rep("American nomads", 4),
# Denali coven
rep("Denali coven", 5),
# Egyptian coven
rep("Egyptian coven", 4),
# European nomads
rep("European nomads", 3),
# Irish coven
rep("Irish coven", 3),
# Romanian coven
rep("Romanian coven", 2)
))Then we use this dataset to make the sunburst chart! Actually creating this plot is not difficult with code (as shown below) but the dataset must be arranged in a very specific way. Check the plotly reference page for specifics.
# plot time
plot_ly(sunburst,
labels = ~labels,
parents = ~parents,
type = 'sunburst') %>%
layout(title = "Characters in the Twilight Saga and their Affiliations")Note that the chart shows the state of each character at the end of the saga, alive/dead status nonwithstanding, as some characters cough BellaSwan cough change groups over the course of the saga.
We grabbed the data for this chart from a useful wikipedia page.
A similar type of graph is the treemap which is, by default, fantastically interactive. We will use the same dataset to demonstrate, so this graph will have the same contents as the previous. Try clicking on different boxes!
plot_ly(
sunburst,
type = 'treemap',
labels = ~labels,
parents = ~parents
)Sadly, this type of graph no longer seems to be supported by plotly. It seems so cool that we had to include it, if for no other reason in the hopes that it will someday be supported and used once again
CONCLUSION
Well, we hope you’ve enjoyed this ride! Hopefully you learned a few new things about Twilight and a few new things about creating interactive plots. We’ve only just begun to scratch the surface of what you can do with plotly. With so many geoms and features, the possibilities of data visualization are endless - the sky’s the limit! We used Twilight to do some pretty basic plots, using just a few variables, so imagine what could be done with larger, more complex data!
ADDITIONAL RESOURCES
As mentioned earlier, the Interactive web-based data visualization with R, plotly, and shiny is a great manual with lots of information about plotly. We reccomend starting with the Overview, then reading the Scattered foundations, then whichever sections are relevant to your project.
Plotly R Open Source Graphing Library has easy-to-follow coding tutorials that can help you make just about any kind of graph, but does not have the in-depth explanations of the previously mentioned guide.
The Plotly cheatsheet from the plotly website is a great tool for refreshing your memory once you know more about plotly, but we wouldn’t reccomend using it to start.
An essential but very confusing resource is the Plotly figure reference, which has a completely comprehensive list of which functions can be used where and what they do. The absolutely comprehensive nature of this resource makes it most useful when you know exactly what you are looking for. We reccomend steering clear of this one until you have gotten your bearings with the first entry on this list, then practiced making graphs with the help of the second entry.
The Plotly Chart Studio is an interesting tool to play around with if you are interesting in creating plotly graphs without coding.