Science Networks: Are scientists working together?
Leila Shokat
Introduction
One of the most common stereotypes about scientists is that they are antisocial, and only work alone in their lab with their microscope and a notebook. Stories like that of Dr. Frankenstein, who toiled away alone in a dark room, emerging weeks later with a horrifying monster, show us why working alone can be bad. There is nobody else around to weigh in on your research, or to tell you whether that human you’re trying to build could actually turn out to be really, really bad. Nature, a very famous scientific research journal, wrote about the importance of collaboration in research. They argue that collaboration is a good way to make scientific discoveries faster, and to do groundbreaking research more quickly.
The field of regeneration is one in which scientists are pushing for such groundbreaking findings. Researchers in this field want to help people heal and regrow their skin, organs, and nerves faster and more seamlessly. To learn more about regeneration, researchers often study axolotls and planarians, pictured here (axolotl on the left, planarian on the right):

Both of these animals are very good at regenerating, so scientists want to learn from them. However, these animals are harder to work with than zebrafish, a more common lab animal, because they are not as widely used and so the tools needed to work with them are not as developed. This means that in these fields of research, a lot of collaboration between different labs could be a huge help to learning about regeneration.
In this blog post, I will look at how much scientists collaborate in three different types of regeneration research: axolotl, planarian, and zebrafish. Out of the three, zebrafish are the most widely used model organism. Planarians and axolotls are both used far less. Are scientists more likely to work together when not a lot is known yet in a given field? I hope to address this question in this blog post by using network analysis.
Loading necessary libraries
To get started, let’s load some packages that we’ll need:
library(easyPubMed)
library(dplyr)
library(knitr)
library(tidyverse)
library(igraph)Network analysis using igraph
In order to answer our questions about how much scientists work with one another across labs, we can make a network diagram. Network diagrams are a great way to visually show how connected or disconnected a collection of things is. An easy way for us to see how much scientists are working together will be to use co-authorship. This means we will look at many papers written within a given field, and keep track of which authors are working together on papers. Generally, what we might expect is that a group of scientists in the same lab will work on a lot of papers together, but might not often branch out to work with scientists from other labs. Our network graph will let us see collaboration visually, so that we can compare the three fields of research we are interested in.
One of the challenges of network analysis is that the data has to be in a very specific format. Here is an example: Let’s say we want to make a network with only two papers, one with two authors and the other with 3. In order to make a network diagram, we need two things.
First, we need a table of the vertices of the network. These are simply the authors of the papers, and will show up on our graph as dots.
| Author |
|---|
| Kelsey |
| Jenna |
| Matt |
| Jacob |
| Emma |
Second, we need a table of the edges of the network. This shows all of the possible pairs of the authors on each paper, and will show up on the graph as lines connecting dots.
| Author 1 | Author 2 | Paper ID |
|---|---|---|
| Kelsey | Jenna | Paper1 |
| Kelsey | Matt | Paper1 |
| Jenna | Matt | Paper1 |
| Jacob | Emma | Paper2 |
Now that we know what our end goal is and what kind of data we need, we can go find and wrangle our data into the right format.
##Grabbing data from PubMed using easyPubMed
PubMed is a huge database that has over 30 million paper citations from science journals. This site is the perfect data source for our question, because the only information we will need are the names of the authors on each paper, and unique paper IDs, which PubMed has. Luckily, there is a package that lets us easily grab data from PubMed and turn it into a data frame!
First, we need to build our query, or search. Using the PubMed “Advanced Search” tool, it is easy to simply enter some search terms, and then copy the exact code to be used with easyPubMed in R. Here is an example of a query that searches for the keywords “axolotl”, “regeneration”, and “limb” from 2010 to the present, and the process of getting from a query to a data frame:
my_query_ax <- '(((axolotl) AND regeneration) AND limb) AND ("2010/01/01"[Date - Publication] : "2020/03/01"[Date - Publication])'
my_query_a <- get_pubmed_ids(my_query_ax)
my_abstracts_xml_a <- fetch_pubmed_data(my_query_a)
all_xml_a <- articles_to_list(my_abstracts_xml_a)
final_df_a <- do.call(rbind, lapply(all_xml_a, article_to_df,
max_chars = -1, getAuthors = TRUE))Using the query, easyPubMed first gets the ID numbers of the papers that your search found. Then, using those IDs, it then fetches some information about those papers, and then finally it will output an easy to work with data frame for us!
Wrangling easyPubMed output into network data
So, now we have a huge dataset with all the authors on over 400 papers about a topic. Let’s remind ourselves what we need in order to make this into a network. First, vertices: a list of all the unique authors in the dataset. And second, edges: all possible pairs of authors within each paper.
Let’s do the easy part first! We can easily make a data frame that lists all of the individual authors, for the vertices (or dots) on our graph:
authors_a <- final_df_a %>%
select(lastname, firstname, address) %>%
unite(name, c("lastname", "firstname"), sep = ", ") %>%
distinct(name)
authors_a %>%
top_n(5) %>%
kable(col.names = c("Author"))| Author |
|---|
| Zou, Yan |
| Zielins, Elizabeth R |
| Ziermann, Janine M |
| Zhang, Yong |
| Zhu, Wei |
Here is the harder part: there is no function in R that will go through our list of papers with their authors and give us a list of all the possible pairs of authors within each paper.
In order to address this problem, I decided to write a function that takes as its input data frame that looks like this:
| Author | PubMed ID |
|---|---|
| Mary | 123 |
| Dan | 123 |
| Charlotte | 123 |
And outputs a data frame that looks like this:
| Author 1 | Author 2 | PubMed ID |
|---|---|---|
| Mary | Dan | 123 |
| Mary | Charlotte | 123 |
| Dan | Charlotte | 123 |
Here is that function:
author_pairs <- function(paper) {
pmid1 = paper[[1,1]]
num_authors = as.numeric(length(paper[[1]]))
num_rows = factorial(num_authors)/(factorial(2)*(factorial(num_authors-2)))
new_data_frame <- as_tibble(t(combn(paper$name, 2))) %>%
mutate(pubMed = pmid1)
colnames(new_data_frame)[1:3] <- c("Author1", "Author2", "pmid")
return(new_data_frame)
}Now that we can make author pairs for a single paper, we can use a for loop to cycle through each paper, apply my author_pairs function, and get the data frame that will be our network edges!
length_pmids_a = as.numeric(length(unique_pmids_a))
for (i in 1:length_pmids_a) {
id = unique_pmids_a[i]
paper <- papers_a %>%
filter(pmid == id)
if (length(paper[[1]]) == 1) {
paper <- bind_rows(paper, tibble(pmid = id, name = "none"))
}
current <- author_pairs(paper)
papers_collab_a <- papers_collab_a %>%
bind_rows(current)
rm(current, id, paper)
}Then we repeat all of these steps for the planaria query and the zebrafish query, so that we can compare the three fields of regeneration research.
Finally, our data is in a format that igraph will let us turn into a pretty network diagram. Let’s see what we can learn just by looking!
Axolotl
scienceNetwork_axolotl <- graph_from_data_frame(d = papers_collab_a,
vertices = authors_a,
directed = FALSE)
plot(scienceNetwork_axolotl, vertex.color = "black", vertex.size = 3, vertex.label = "")
Planaria

Zebrafish

Comparison of network density
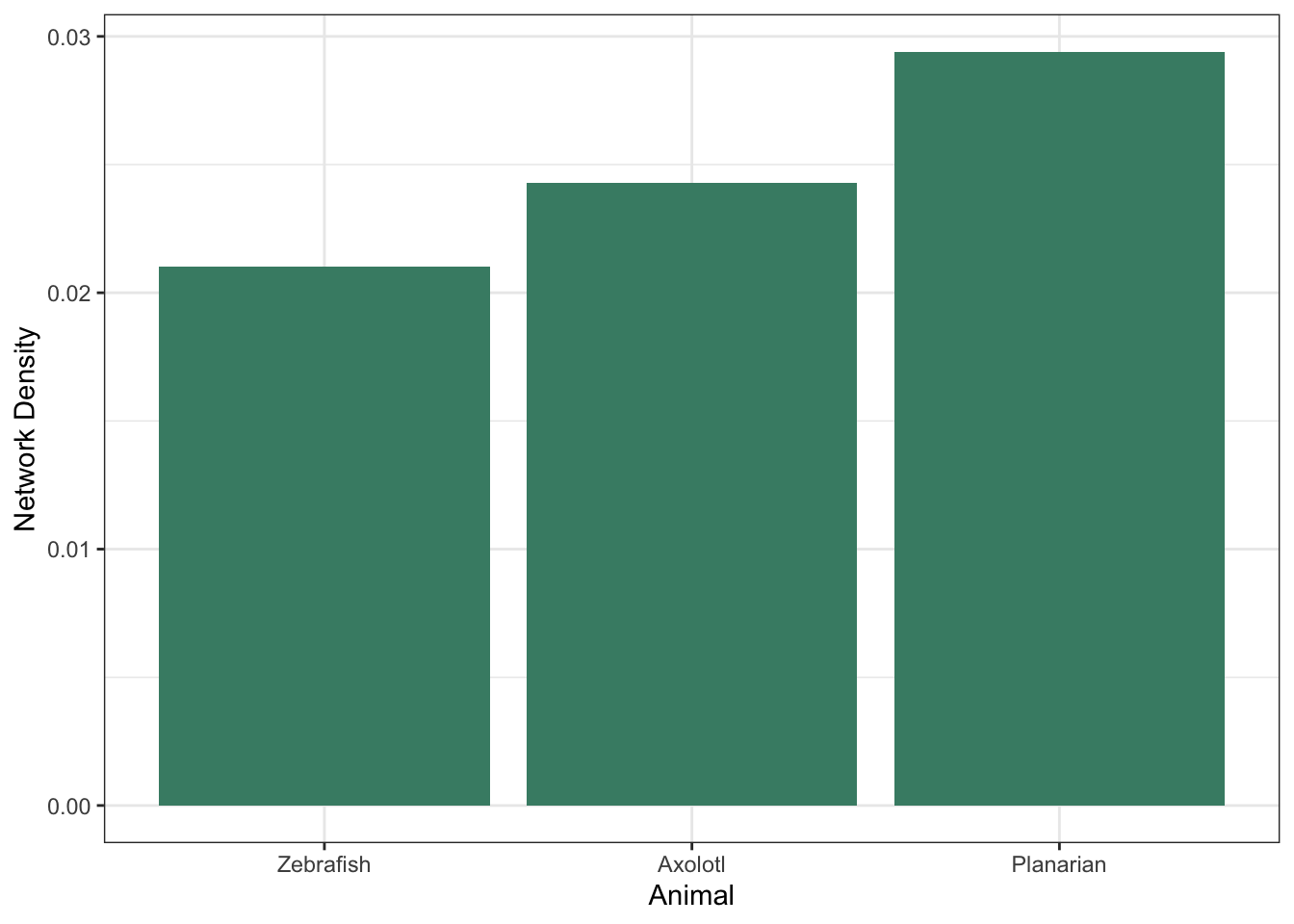
Analysis
Looking at these networks visually, it becomes clear that the zebrafish regeneration field is less collaborative overall than either the axolotl or planarian field. This can be seen in the number of clusters that are not connected to the central clusters in each plot: there seem to be more isolated labs in the zebrafish plot than in the axolotl or planaria plot. To quantify this, the graph of network density looks at the total connections in the network, over the total possible connections that could exist in the network. This means that we can compare networks regardless of their size, and make conclusions about how connected, or collaborative, they are. In this graph, we can see that the zebrafish network is, in fact, the least collaborative of the three, followed by the axolotl network and finally the planaria network.
Conclusions
These results show that, within the study of regeneration, there is relatively more collaboration in the field of planaria research than in axolotl or zebrafish research. I would like to suggest that this could be because the field of planaria research is not as popularized, and therefore many of the tools and methods that people use need to be shared. For example, if you want to know how to do a particular experiment with zebrafish, there are probably many papers you can read that will explain how to do that. If you are trying to do an experiment on planarians, however, there is less likely to be a lot of existing literature, creating the need for collaboration and resource sharing. The fact that this field is not very far along, then, makes researchers work together more than they would otherwise need to. This is simply one explanation for the trend that we see, and there are conflicting views on whether collaboration is inherently good, or whether the issue is more complicated than that. Many more questions could be asked on this subject, and I would encourage readers to make use of visual network analysis with igraph in order to ask them!
Bibliography
Images
Axolotl image
Planarian image
Packages
dplyr: Hadley Wickham, Romain François, Lionel Henry and Kirill Müller (2020). dplyr: A Grammar
of Data Manipulation. R package version 0.8.4. https://CRAN.R-project.org/package=dplyr
easyPubMed: Damiano Fantini (2019). easyPubMed: Search and Retrieve Scientific Publication Records
from PubMed. R package version 2.13. https://CRAN.R-project.org/package=easyPubMed
igraph: Csardi G, Nepusz T: The igraph software package for complex network research,
InterJournal, Complex Systems 1695. 2006. http://igraph.org
knitr: Yihui Xie (2020). knitr: A General-Purpose Package for Dynamic Report Generation in R. R
package version 1.27.
tidyverse: Wickham et al., (2019). Welcome to the tidyverse. Journal of Open Source Software, 4(43),
1686, https://doi.org/10.21105/joss.01686