Looking at a Board Game Collection Like a Data Scientist
Maddy Doak, Josh Reiss
At the start of this project, we wanted to dive into something we’ve investigated at a casual level for over a year now: board games. We’ve both become deeply invested in board games as a hobby, and realized within a few months of research that one of the best resources for learning about board games is the Board Game Geek (BGG) website.
This led to a data science project centered on data pulled from BGG using the BGG XML API2, a revised version of the original API. This API allows a given user to pull information about board game collections for a single user, individual board games, or even many different games at once. This does not require an API key like many APIs do; instead, they limit requests from any user to every 5 seconds. If you try to make requests any faster than that, you just get an error.
It was ultimately decided that the best way to learn about a set of board games, without simply picking the top ‘n’ examples, would be to take a single user’s collection. But what if you wanted to learn more about your own collection of board games, not just the collection owned by the person who did the data analysis? Thus, we decided that instead of simply doing all the wrangling on our own board game collection, we would make an application that would allow anyone to examine any public BGG user’s collection of board games in greater detail.
And so, a Shiny app was born. This app allows anyone to enter a valid username from BGG, and see that user’s entire collection (visualized using thumbnails), as well as summary statistics about their collection (in this case, we provided a calculation of the average rating and difficulty of the games), as well as a word cloud of the most common words in reviews of all of the games. In addition, a graph is generated representing even further information about the games. This graph has an interesting origin story.
Several posts on the internet (1, 2, 3, along with likely many more) have done their own analyses of data from BGG and discovered something quite interesting: ratings are biased according to complexity. In short, the more complicated or difficult a game is, the more likely users are to rate it better than an easier game of similar quality. There are many possible factors behind this trend, but regardless of the cause it is an interesting pattern. We believe the best analysis and breakdown of this phenomenon is found in the third source listed above, on a blog dedicated to Python and data analysis by Dinesh Vatvani.
As a result of this finding, we decided to include a graph comparing weight (difficulty) and ranking of the board games in a user’s colleciton. Lo and behold, the pattern held true, with a very significant p-value (<< 0.001) and an adjusted R-squared value of 0.405 (moderately positive):
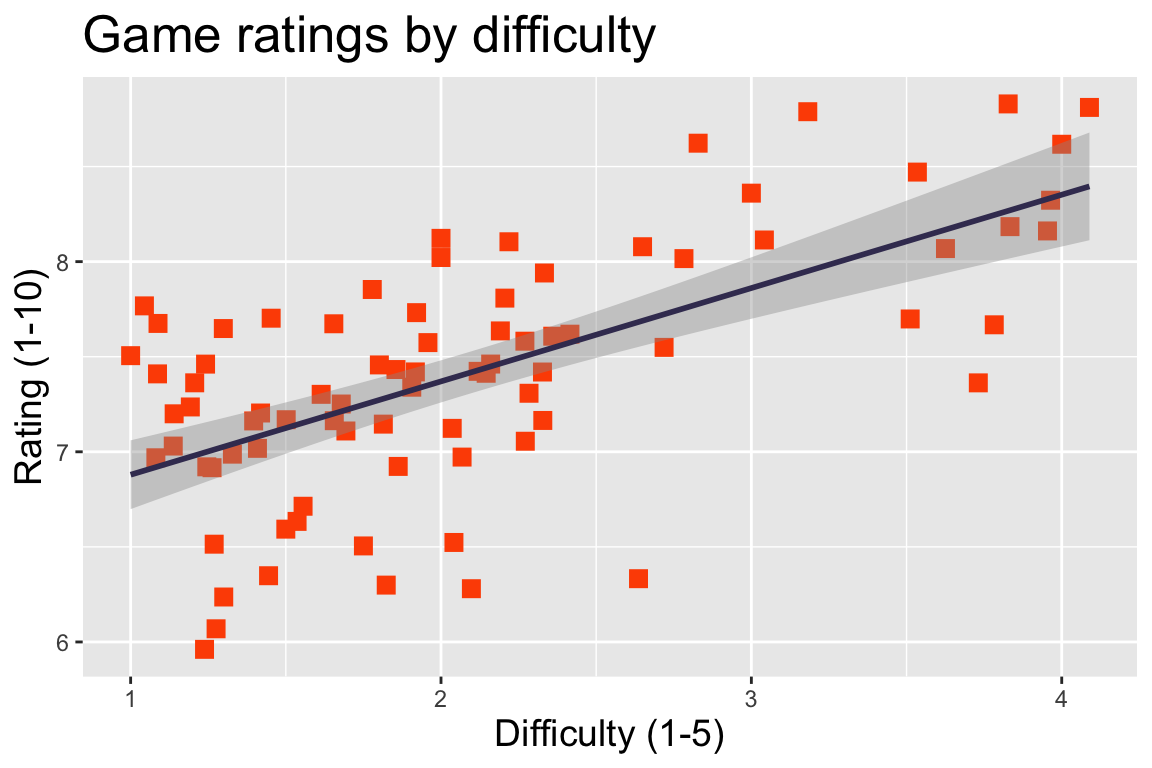
It’s important to explain what those terms mean. Basically, the p-value describes the likelihood that the result we see would occur purely by chance; since the chance is far less than 1 / 1000, there is support for the idea that the pattern we see is significant, and that there is a relationship between game difficulty and rating.
The R-squared (or adjusted R-squared) value represents how strong this relationship is, on a scale from -1 to 1. If the R-squared value is -1, then there is a perfect ‘negative’ correlation; this does not mean that they’re perfectly unrelated to each other. In fact, this means that there is a perfect relationship between the two parts: when one goes up by a certain amount, the other goes down by a certain amount, across all possible values that were measured. An R-squared of 1 says something similar: whenever one of the factors goes up, so does the other, and this relationship is perfect across all measured data. An R-squared of 0 is perfectly imperfect: there is no relationship whatsoever (that we can see) between the variables.
The R-squared for the graph above is about halfway between 0 and 1; there is a ‘medium’ positive correlation between game rating and difficulty, according to our data set. This means that as a game’s difficulty increases, the rating tends to as well, but this relationship isn’t extremely strong, or necessarily true in all cases. It’s just that: a tendency.
Even so, it is interesting to note this tendency. Websites like BGG are far from being flawless datasets. It is very possible that the sorts of people who are likely to engage with a rating site such as BGG are going to be more heavily invested in boardgaming as a hobby, and therefore more likely to enjoy ‘heavy’ games. On that note – what even is a ‘heavy’ game? What does ‘weight’ represent? A game with an extremely complicated set of rules such as Twilight Imperium is considered to be high-weight. However, rules-light but strategy-heavy games like chess are considered to be decently heavy by the BGG community (the average weight rating on the site for chess as of writing this is 3.71 out of 5).
Not only is weight nebulously defined, it is likely that a given game’s weight rating will tend to have response bias. Speaking from personal experience, we are much more likely to vote on how heavy a game is if the game’s weight surprises us, or if it is extremely heavy. We don’t pick up a party game and feel the need to go vote for a 1 out of 5, but if a game we had expected to be a 2 is more like a 4 in our opinion, we’ll be sure to throw in our two cents.
All this is to say: BGG is an incredibly powerful and interesting source of data, but it is nonetheless a flawed source. The conclusions that can be drawn from it are interesting, but need to be taken with a grain of salt (or, more realistically, a few teaspoons). It is a useful guide for purchasing decisions (e.g., don’t buy a heavy game if you’re planning to bring it to the family Scrabble night), and it is a helpful tool for determining if you have time to play a game (if the average BGG user thinks a game will take 3 hours, and the box says it will take 30 minutes, the box is probably the less reliable source), but it’s worth considering that 4.5% of BGG users who voted on chess’ best playercount say that it’s best played with 3 or more players.
If any of this seems interesting, we highly recommend checking out the app we built, in the BGGShinyApp folder of this repository. (A sample username has been provided, if you don’t have one in mind.) The statistics and visuals included in the app aren’t incredibly sophisticated, but they’re an interesting exploration of the information you can get out of BGG’s API. We hope you find the insights…well, insightful!