Which Ryan Gosling film should you watch next?
Jacob Goldsmith, Sarah Maebius, and Claire Milander-Mashlan
Analyzing the success of movies with Ryan Gosling

© 2014 Getty Images
Ryan Gosling is a well-known Canadian actor and singer who has played roles in award-winning films and received many awards himself for his performances in those films. In this post, we explore the critic and audience scores along with the earnings and awards of the 27 films in which Ryan Gosling stars. The critic scores and audience scores were taken from Rotten Tomatoes. To reach this stage of analysis, we will first walk through the steps to converting data from the internet into a format that is friendly for analysis.
Wrangling the Data
Before we can analyze the recognition Ryan Gosling’s cinematic masterpieces have deserved, we must first gather together the data. We’ll do that with these R packages:
library(tidyverse)
library(rvest)
library(anytime)
library(lubridate)First, we’re going to use grab data on one of his movies from Wikipedia using the rvest package. Let’s pick ‘La La Land’ (link can be found here).

© Lionsgate
#reads in the data
url_land <- "https://en.wikipedia.org/wiki/List_of_accolades_received_by_La_La_Land"
#creates a list of tables found at that url
tables_land <- url_land %>%
read_html() %>%
html_nodes(css = "table")
#picks out the table we want and turns it into a data frame
awards_land <- html_table(tables_land[[3]], fill = TRUE)Now we have a data frame from Wikipedia, but it’s not very tidy.

The first thing we’ll want to do is create a column for the film name, since we’ll be joining it with all of Ryan Gosling’s other films and want to make sure we can identify which award belongs to which film. We also want to rename a couple columns, and only select the columns from the Wikipedia table we care about. This is all done with the tidyverse. Lastly, we’ll want to pull out just the year from the “Date of Ceremony” column, using the anytime and lubridate packages.
awards_land <- awards_land %>%
mutate(Film = "La La Land (2016)") %>%
rename(Recipients = `Recipient(s) and nominee(s)`,
Year = `Date of ceremony`) %>%
select(Award, Year, Category, Recipients, Result, Film)
awards_land$Year <- anydate(awards_land$Year)
awards_land$Year <- year(awards_land$Year)
Much better! But there’s a major problem to fix. The values for the column Result are inconsistent.
unique(awards_land$Result)
It looks like we’ll have to change a lot of these values, so instead writing the mutate() function over and over, let’s create a small function to do that for us.
rename_value <- function(data, x, old_value, new_value){
x <- enquo(x)
data <- data %>%
dplyr::mutate(!! quo_name(x) := dplyr::if_else(
!!x == old_value, new_value, !!x
))
return(data)
}Now this…
awards_land <- awards_land %>%
mutate(Result := if_else(
Result == "Won[a]", "Won", Result
))…becomes this:
awards_land <- rename_value(awards_land, Result, "Won[a]", "Won")But that’s not good enough! We want to rename multiple values, so we’ll create a for loop. To do this, we have to create lists of both the old and new values. Then, we can tell R to use the function rename_value() for every entry in the paired lists.
#list of old values, made with specific entries in the unique Results list
old_values_land <- unique(awards_land$Result)[c(4, 6, 10, 11, 12, 13, 14, 15, 16, 17)]
#list of new values
awards_land_clean <- c("Won", "2nd Place", "2nd Place", "2nd Place", "Won", "2nd Place",
"2nd Place", "3rd Place", "6th Place", "9th Place")
for(i in seq_along(awards_land_clean)){
awards_land <- rename_value(awards_land, Result, old_values_land[i], awards_land_clean[i])
}
unique(awards_land$Result)
Much better! We’ll repeat this for each of this movies, then join the rows of each dataframe together into a master using rowbind() – we’ll call that awards_list_master.
However, not all of Ryan Gosling’s films won an award. That doesn’t mean they shouldn’t be recognized! We’ll take a list of a single column of film name, called film_list, and anti_join() with awards_list_master to find out which films are present in film_list but not awards_list_master. Then, we’ll use full_join() to join the two lists, which will create an NA in every column except for Film if the film doesn’t have any awards.
awards_none <- anti_join(film_list, awards_list_master)
awards_list_master <- full_join(awards_list_master, awards_none)Now that we have a complete dataset of every award Ryan Gosling films have ever been nominated for, let’s ask a simple question - how many awards did each film win? We’ll collapse the Result column into three outcomes: “Won”, “Didn’t win”, or “No Award”, and count them up by film.
awards_list_count <- awards_list_master %>%
mutate(Outcome = case_when(
Result == "Won" ~ "Won",
Result != "Won" ~ "Didn't Win",
is.na(Result) ~ "No Award"
)) %>%
group_by(Outcome, Film) %>%
count(Outcome)Now we have a second, smaller dataset that answers this question - take a look!
library(DT)
datatable(awards_list_count)Visualization
There are an almost unlimited number of questions that we can ask of these data, but some of them are more interesting than others. First, we’ll start with a some simple visualization for these data using ggplot2 within the tidyverse package.
To create a stacked histogram demonstrating the number of awards that the Gosling films received nominations for, along with the number of awards actually won by the films, we first had to collapse the awards_list_master dataset to get the total number of awards withing each film that were nominated and lost, nominated and won, or not nominated at all. The case_when() function comes in handy for this task. Next, if we want to arrange the films by year instead of alphabetically by name, we had to extract a vector from the film names that contained only the years of the film.
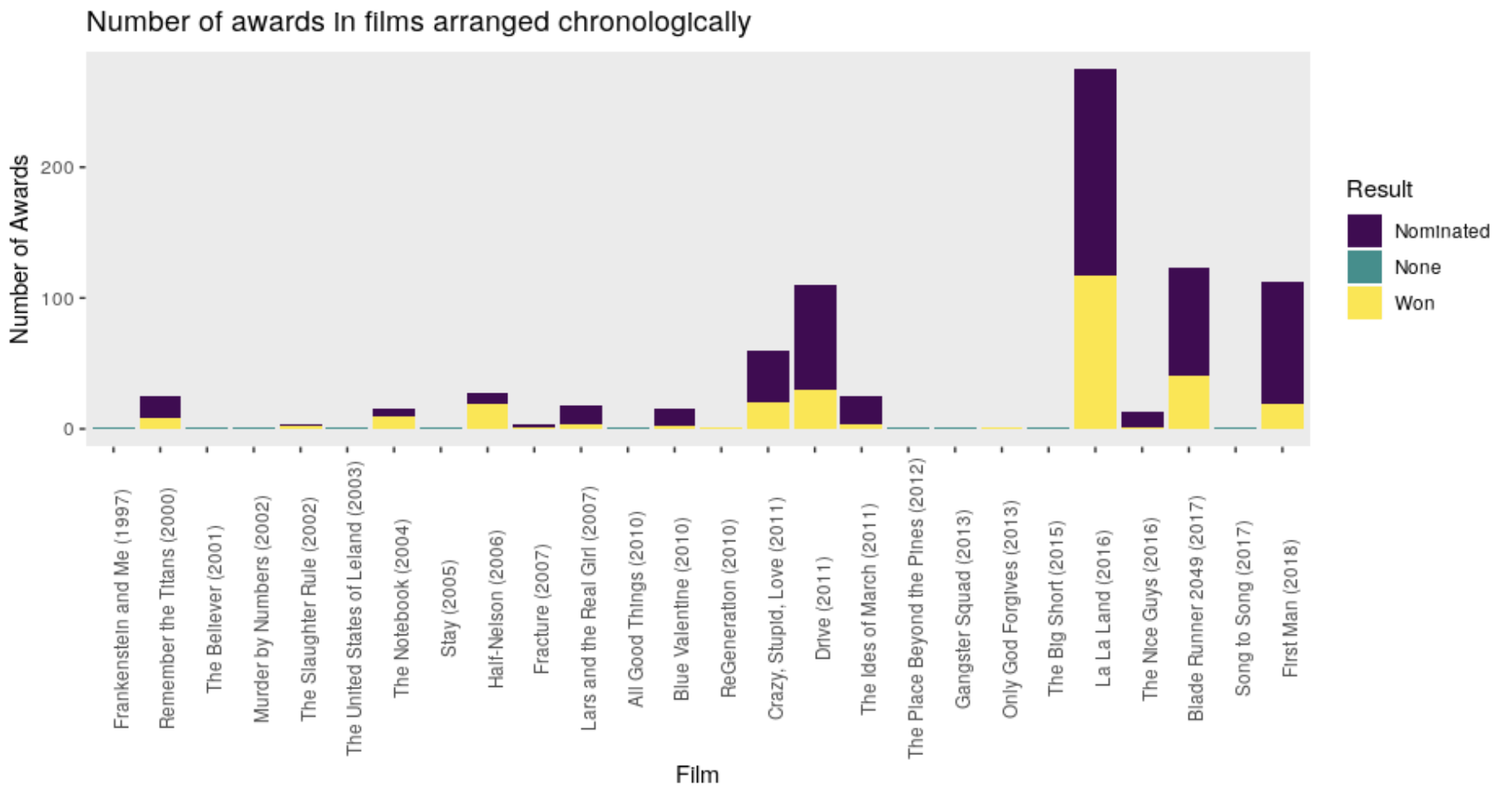
Looking at the number of awards for Ryan Gosling films were nominated for over time, it appears that the second half of the actor’s career has been the most successful in terms of critical acclaim. The most notable film according to this graph is ‘La La Land’ with around 300 award nominations, 117 of which the film won.
However, this graph doesn’t tell you whether or not YOU would be likely to enjoy the movie. How can we find that out?
One interesting question this brings up is whether audiences and critics tend to agree about the quality of Ryan Gosling films. Does Ryan Gosling’s appeal transcend cinematic perspective, captivating audiences and critics alike? Let’s see if the data from rotten tomatoes give us a clue, using a dataset called gosling_films which contains the variables critic_score, audience_score, and total_awards:
# identifying movies which critics and audiences disagreed by more than 20%
score_outliers <- gosling_films %>%
filter(critic_score - audience_score > 20)
score_outliers2 <- gosling_films %>%
filter(audience_score - critic_score > 20)
# the meat of the plot
ggplot(gosling_films, aes(x = critic_score, y = audience_score)) +
geom_point() +
# adding a line that would represent perfect critic-audience agreement
geom_abline(intercept = 0, slope = 1, color = "white", size = 1) +
# labelling outliers
geom_text_repel(score_outliers, mapping = aes(label = Film)) +
geom_text_repel(score_outliers2, mapping = aes(label = Film)) +
... 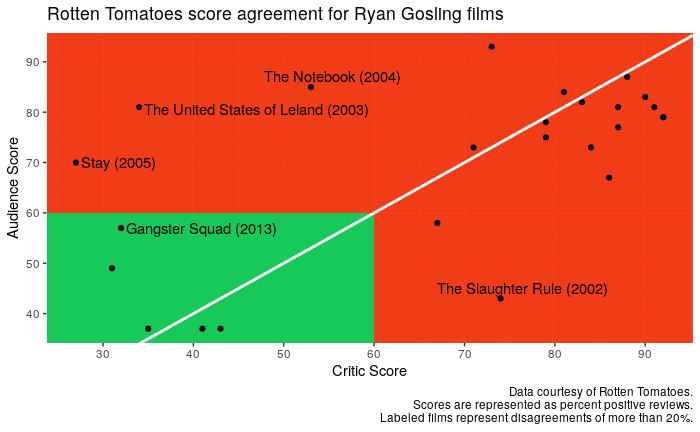
Most of his films seem to be reasonably close to the line at \(y = x\), representing the case where the critic score equals the audience score. However, there are four outliers where audiences loved a film but critics were more sour. Interestingly, these four films don’t have a whole lot in common.
Of course, we all know ‘The Notebook’ (2004), a hit rom-com with a message that now looks rather problematic. ‘Stay’ (2005) and ‘The United States of Leland’ (2003) are psychological dramas, clearly attempts at making a serious film that failed to resonate with critics. Finally, the action drama ‘Gangster Squad’ (2013) failed to impress audiences or critics, but audiences were relatively more tolerant of its lazy writing, over the top violence, and lack of creativity.
There’s only one movie that did significantly better with critics than audiences, ‘The Slaughter Rule’ (2002), an indie art film done towards the beginning of Gosling’s career.
Overall, we really don’t see a dichotomy between mass-market films aimed at audiences and more artsy films aimed at critics. Instead, it looks like most of the movies that did better with audiences than with critics were serious films that simply missed the mark with critics, but audiences were more forgiving of their faults. Gosling’s best films, like ‘La La Land’ (2016), ‘The Big Short’ (2015), and ‘Half-Nelson’ (2006) were hits with audiences and critics alike.
Does this mean I have to watch ‘La La Land’ now?
We’ve seen that critic and audience scores are generally similar for the majority of Ryan Gosling films – does this mean that the number of awards a film is nominated for will predict audience score? We’ll go back to gosling_films and plot total_awards against audience_score.
ggplot(gosling_films, aes(y = total_awards, x = audience_score)) +
geom_point() +
stat_smooth() +
...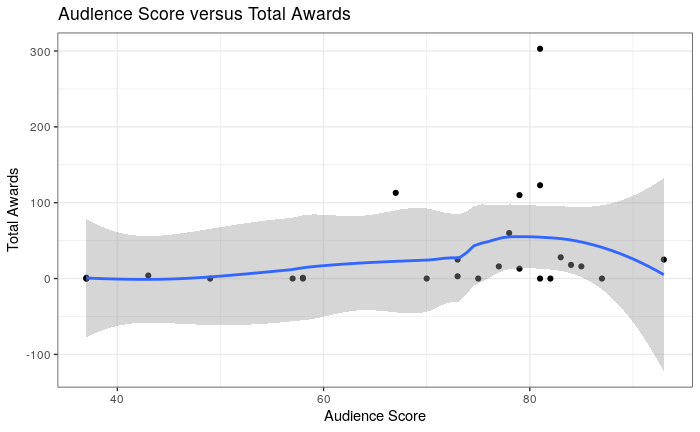
There’s no relationship between the number of awards a Ryan Gosling film was nominated for and the audience rating, so a heavily-awarded film is not necessarily going to be more enjoyable to watch.


The authors’ favorite Ryan Gosling films, the star-studded rom-com ‘Crazy, Stupid, Love’ and quirky indie romance ‘Lars and the Real Girl’ both were in the middle of the pack when it came to award nominations but had both high audience and critic ratings. In conclusion, feel free to pick a random Ryan Gosling film, because chances are you’ll enjoy it.
Resources
A good resource for learning how to customize ggplots can be found at the Data Novia blog here.
This project was inspired in part by David Robinson’s blog post, Analyzing networks of characters in ‘Love Actually’, a rom-com which is objectively worse than ‘The Notebook’.