Reshaping Your Data in Stata
Often when importing data, your data will be in wide format. Wide format is when every person takes up one line with all of their observations spreading across the page. However, the way Stata runs repeated-measure ANOVAs requires the data to be in long format. Long format is when each observation of each person is its own line. While this is immensely tedious to switch by hand, the reshape command makes switching between wide and long format nearly effortless. Best of all, it's completely reversible.
Using the reshape command requires a few things of your data. The first of these is that each person has a unique identifier, like an ID number. If your data does not currently contain such an identifier, you can add an arbitrary one since it is only there for Stata to know which data points go with which individual. The easiest way to do this is to type generate id= _n into the Command window. _n is Stata's way of referring to the line numbers and so this command will generate a new numeric variable that identifies the first case in your data set as 1 and then numbers those that follow sequentially. Make sure you put a space between the = and the _n or the command will not work. Additionally, while this command will work if your data is in wide format it will not work if your data is in long format; in this case you will need to enter the identifier manually so data is grouped properly.
The only other thing to be aware of when switching from a long to wide data format is that multiple observations need to have a similar naming scheme. For instance, if I have three happiness observations I would want them to have names like hap1, hap2 and hap3. This naming scheme tells Stata that they're different observations of the same variable. If your variables were, for instance, hap1, happy2 and hap3, you would rename happy2 hap2 and then proceed.
The basic command reshape is followed by which direction long or wide you want to reshape the data. Then comes the variables being reshaped. Next is the first part of the argument i([id variable]) followed by the dimension you're reshaping on j([incremental variable)
While that seems very confusing, in practice it is fairly simple. Take for example the following three person data set currently in wide format:

To put that data into long format, the command would be as follows reshape long intrint ext, i(id) j(time)
When processing a reshape command Stata's Results window will display the following information detailing what it did with each variable. The j argument creates a new variable which should describe what

Now if I browse my data, it is in a long format:
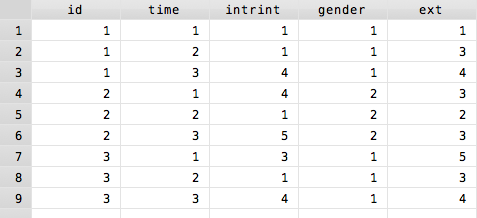
Notice that since I did not mention gender in the reshape syntax, Stata assumes it is constant. If gender were a string variable, the result would be unchanged: all variables not mentioned are assumed constant. Similarly, the i() argument can accommodate multiple identifiers; for example, I might have a dataset with ID numbers and survey numbers. In this case, the command might look more like this: reshape long intrint ext, i(id survey) j(time)
In some cases, there is more than one way to reshape the data. The following example is taken from [D] reshape (the official Stata Data Management manual) and involves multiple levels of sorting variables. Click here to download these lines of data to play with. Below, is the data displayed in the longest possible format (it will download in this format).

Below is the same data in the widest possible format:

The following chart explains how to switch between these various formats, giving both a good idea of reshape's full capabilities and how to use them. Note in cases of going from long-long to wide-wide, multiple reshape commands are necessary.

This example also introduces two new options of the reshape command. The first of these, the @ tells Stata where to stop reading the name of a variable. So if the variable was named inc80, and I wanted the variable to be inc when it switched formats, I would specify reshape inc@ By putting the @ sign before inc, Stata knows to make inc for males minc and inc for females finc, using the sex variable as specified in j, the f and m. If this does not make sense, play around with it for a few minutes.
The other useful option is string which tells Stata that the the variable specified in j() is a string variable.
Finally, note that reshape is somewhat reversible. Specifically, you can move back one iteration. For example, if you type reshape long after you have reshaped the data to be wide, Stata will revert the data.
Back to Repeated-Measures ANOVA